June 19, 2026
Agentic AI Architecture: Patterns, Components & Examples

Most posts about agentic AI architecture start with the components and end with a vendor pitch. The harder problem, and the one that decides whether an agentic system makes it to production, lives between them. It comes down to which architectural decisions you make about how those components fit together, who owns them, and how they evolve as your system learns what it actually needs.
This guide covers what agentic AI architecture is, the four core components that appear in nearly every production design, the patterns teams choose among, a reference architecture you can adapt, the decisions you'll face along the way, real-world examples, and the production challenges that catch teams off guard. It's written for architects, engineering leaders, and technical founders building agentic systems that must withstand contact with real users.
What Is Agentic AI Architecture?
Agentic AI architecture is a system design that enables large language models to act autonomously by perceiving context, reasoning over options, retaining memory across steps, and taking action through tools. It's the structural decision layer beneath every production AI agent, and it's where most "this worked in a demo but failed in production" stories actually live.
The shift from traditional AI to agentic AI is mostly a shift in path dependence. Many traditional ML inference pipelines are designed to behave deterministically for the same input. An agent, given the same input, can take a different path. It might choose a different tool, plan a different sequence of steps, or ask a different clarifying question. That variability is the point. It's also the source of every production challenge in the rest of this guide.
Here is a useful framing. Agentic architecture is an architecture decision, not a framework choice. The interesting choices concern which kind of reasoning, which memory model, which tool boundary, which human-in-the-loop posture, and how the whole thing is governed. Picking LangChain, LlamaIndex, or Bedrock is a downstream consequence of those decisions, not a substitute for them. We've written elsewhere about emerging architecture patterns for the AI-native enterprise; agentic systems are the most demanding case of that broader shift.
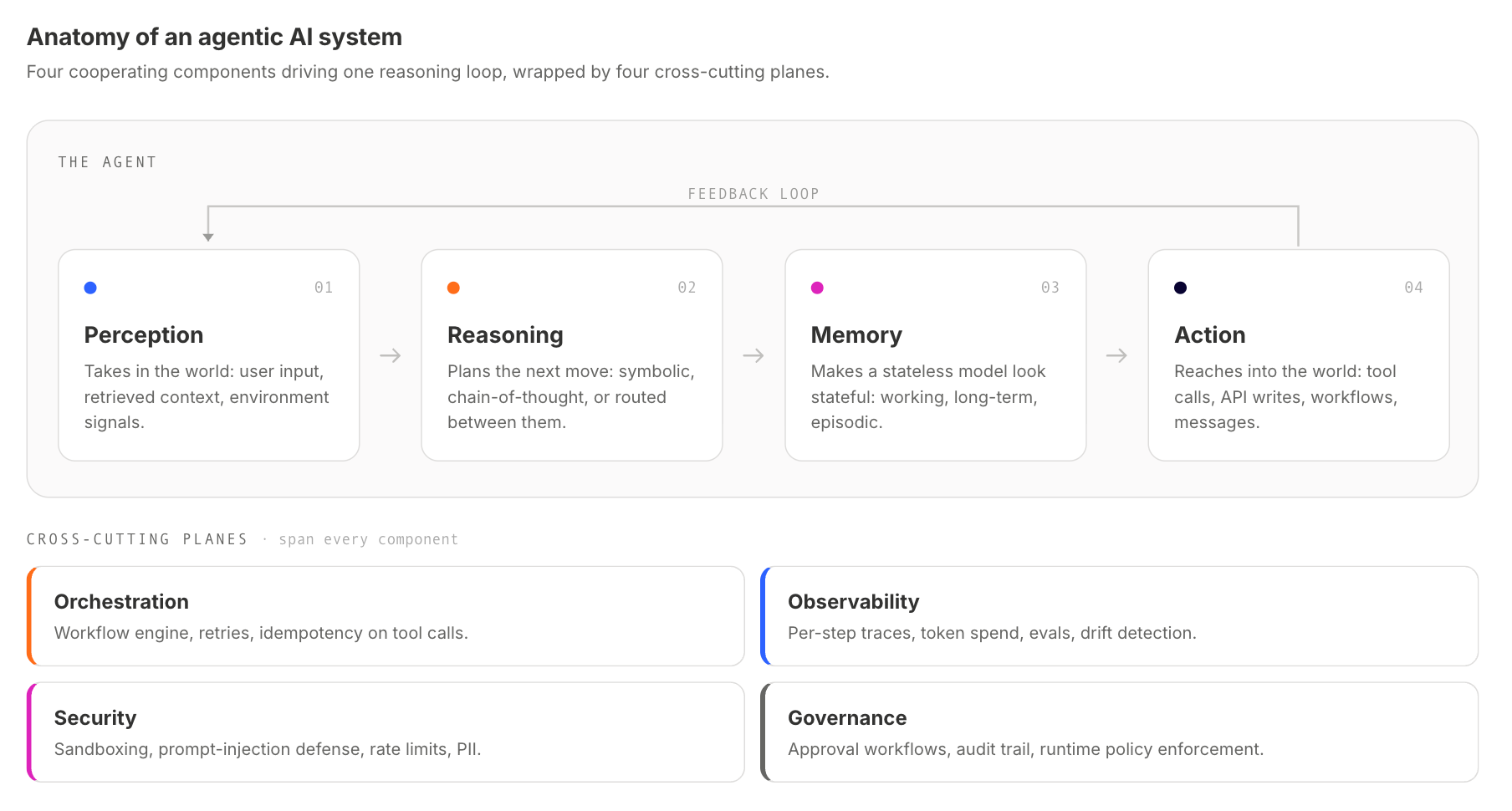
The Four Core Components of an Agentic AI System
Nearly every production agentic system can be described as four cooperating components. Vendors differ on the labels (perception/cognition/action/learning, or input/reason/memory/act, or any of a dozen variations), but the conceptual carving up is consistent.
Perception
Perception is how the agent takes in the world. In practice, that means structured inputs (user messages, API payloads, retrieved documents), context the agent gathers itself (tool descriptors, prior conversation, retrieved knowledge), and signals from the environment in which it's deployed. The interesting design choice here is what counts as context that the agent should care about. Too little, and it can't reason. Too much, and you're paying for tokens that confuse the model rather than ground it.
Reasoning
Reasoning is how the agent gets from "here's what's happening" to "here's what to do." Three approaches dominate:
- Symbolic reasoning. Rule-based logic, decision trees, or knowledge-graph traversal. Predictable, cheap, brittle to novel inputs.
- LLM-based chain-of-thought. The model breaks a goal into steps, evaluates each, and revises. Flexible, expensive per token, sensitive to prompt design.
- Planning algorithms. Search-based planners or task decomposers that explore option spaces before committing. Useful when the action space is large and partly reversible.
Production systems rarely pick one. They route easier tasks to cheaper paths and reserve the chain of thought for ambiguous cases. That routing is itself an architectural decision.
Memory
LLMs are stateless. Memory in agentic architecture is what makes the system look stateful to the user. Three flavors matter:
- Short-term/working memory. The conversation or task currently in progress.
- Long-term memory. User preferences, prior outcomes, and patterns the agent has observed are typically stored as embeddings in a vector store.
- Episodic memory. Discrete experiences (resolved tickets, completed transactions, prior decisions) that the agent can retrieve to inform new ones.
Most "the agent forgot what we discussed" complaints are architecture problems disguised as model problems.
Action
Action is where the agent reaches into the world: function calls, API invocations, database writes, sending messages, and kicking off workflows. The architectural choice that matters here is what permissions the agent gets and how it earns them. A sandboxed read-only agent is almost trivial to ship. An agent that can spend money, change customer records, or modify infrastructure needs careful guardrails. We've written elsewhere about why language models alone aren't sufficient for many agentic use cases (Beyond LLMs covers the case); the action layer is one of the places that limitation shows up most concretely.
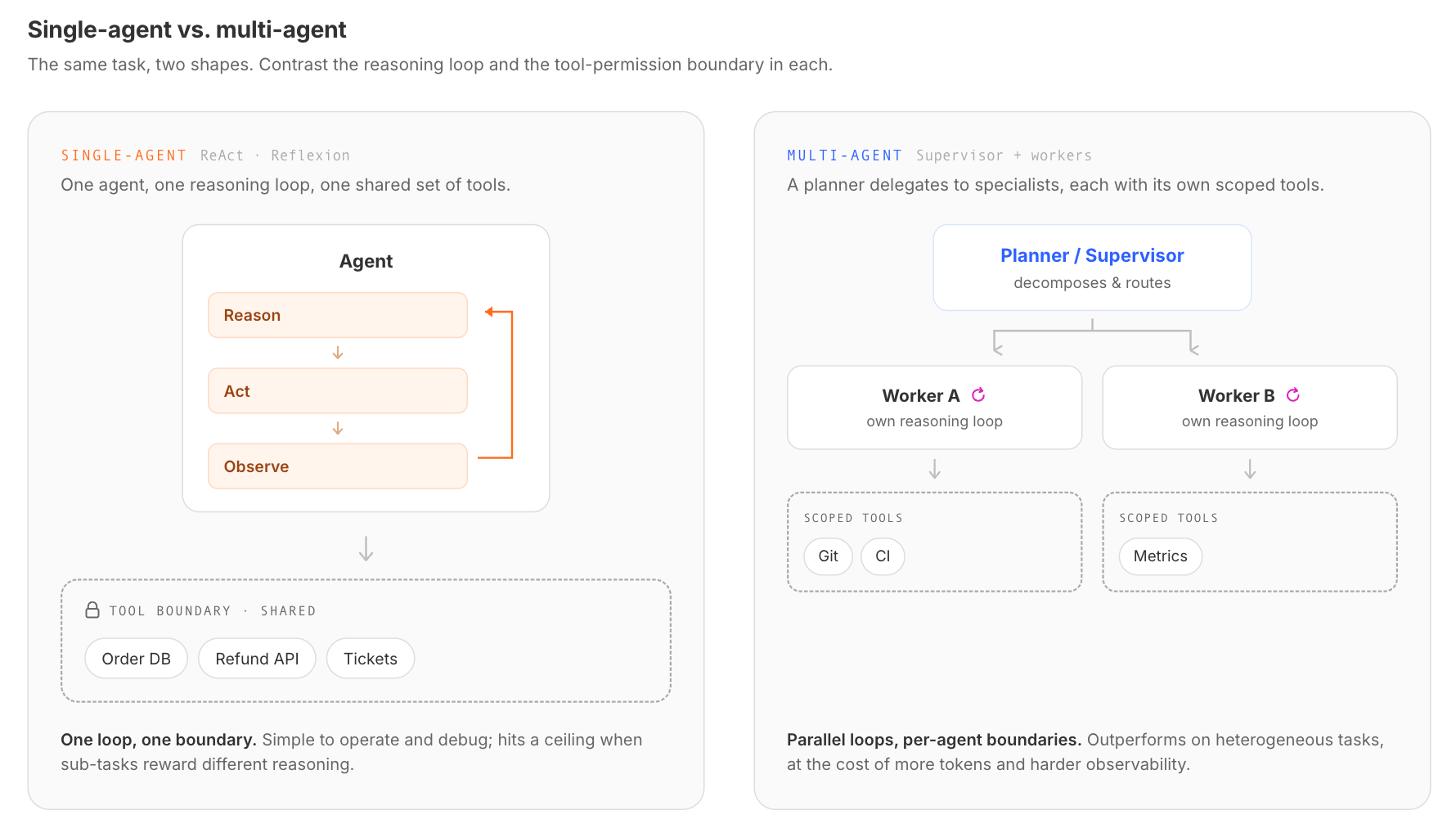
Common Agentic AI Architecture Patterns
Past the four components, the next decision is the shape of the system: how many agents, how they coordinate, and who supervises whom. A handful of patterns recur in practice.
Single-Agent (ReAct, Reflexion)
One agent, one reasoning loop, one set of tools, simple to operate and easy to debug. The design hits a ceiling when the task space is broad or when different sub-tasks reward different kinds of reasoning. ReAct interleaves reasoning steps with tool calls; Reflexion adds self-critique on each step. Both are still single-agent designs.
Multi-Agent Collaboration
Multiple agents share a problem and exchange messages to solve it. A router-and-workers pattern, a debate pattern where two agents argue toward a better answer, a voting pattern where several agents propose and one selects. Multi-agent systems can outperform a single chain-of-thought on tasks where parallel exploration helps, at the cost of higher token spend and harder observability. We've explored the fundamentals of supercharging AI with multi-agent systems in more depth.
Hierarchical (Supervisor + Workers)
A supervisor agent delegates to specialist worker agents. Specialists return results; the supervisor synthesizes. This works well when sub-tasks are heterogeneous and a single planner can usefully route between them. The trade-off is that the supervisor becomes the bottleneck, and its prompt becomes the most important artifact in the system.
Graph-Based / Mesh
Agents are nodes in a graph and pass messages along defined edges rather than through a central coordinator. Useful for workflows where the system topology mirrors a real process (a supply chain, a multi-step approval process, a research pipeline). Higher operational complexity than hierarchical designs.
Reflection and Self-Correction
A control loop where the agent evaluates its own output against criteria and revises before returning. Easy to layer onto any of the patterns above. The risk is reflection that's too cheap (the agent always thinks it did well) or too expensive (the agent spirals). Calibrating it is empirical.
Reference Architecture for Production Agentic AI
Once the patterns get composed into a real system, the architecture looks less like "four boxes" and more like four boxes plus four cross-cutting planes that hold the whole thing together. A workable reference shape:
- Tool layer. Curated APIs, MCP servers, databases, and downstream services the agent can call, plus per-tool permission scoping.
- Reasoning layer. Model routing (which LLM for which step), prompt management, and the planner/critic loops.
- Memory layer. Short-term context, long-term vector store, and episodic retrieval, with clear write and eviction policies.
- Orchestration. Workflow engine (Temporal, Airflow, custom), retry/backoff, and idempotency guarantees on tool calls.
- Observability. Traces of every reasoning step, token spend per request, eval harness, and drift detection on output quality.
- Security. Sandboxing, prompt injection defenses, tool-call rate limits, PII handling.
- Governance. Approval workflows for high-risk actions, audit trail, and policy enforcement.
The planes deserve more attention than they usually get. Orchestration sounds like infrastructure, but actually drives correctness. A tool call that succeeds halfway through a multi-step workflow with no idempotency guarantee is the agentic equivalent of a database write without a transaction. Observability is the difference between a system you can improve and one you can only redeploy. Security at the agent boundary is structurally different from security at the API boundary: an attacker doesn't need to bypass authentication if they can convince the agent to act on their behalf. Governance is where the decisions you made at design time get enforced at runtime, including the ones you made implicitly.
This is the layer where Catio's own multi-agent recommendation engine for enterprise architecture lives. The team that built it has been writing about the decisions that shape it; the high-level shape is genuinely four cooperating components plus four planes, and the planes have turned out to be more interesting than the components.
Architecture Decisions You'll Face When Building Agentic Systems
The component list and the patterns are well-rehearsed at this point. The real leverage is in the decisions about how to combine them.
Symbolic vs. LLM-Based Reasoning
Cost per call, latency, and predictability all favor symbolic reasoning. Flexibility and handling of edge cases favor LLM-based. Most production systems route between them based on confidence thresholds and task type. The decision to write down isn't "which one" but "what determines the route."
Single LLM vs. Multi-LLM Routing
A single model is simpler. Multi-model routing lets you send simple tasks to cheaper models and reserve more capable ones for ambiguous or high-risk steps, which can meaningfully reduce token spend, depending on the workload mix. The catch is that your evals now have to cover behavior at the routing boundary, not just per-model.
Stateless Agents vs. Stateful with Memory
Stateless agents are easier to operate and reason about. Stateful agents are required for most production use cases. The decision is what category of state belongs in the conversation context, what belongs in long-term memory, and what belongs back in your primary application database. Lumping all three together is the most common architecture mistake we see.
Human-in-the-Loop vs. Fully Autonomous
This is a spectrum, not a switch, and the right answer is usually per-action: low-risk actions are autonomous, while high-risk actions require approval. The architectural decision is how the agent communicates which category an action falls into and how that gets reviewed.
Sandboxed vs. Tool-Permissioned Actions
A sandboxed agent can't break much. A tool-permissioned agent can act with real effect, which is the whole point of agentic systems. Most production designs land on tool-by-tool permissioning with capability-based access controls, audit trail, and rate limits. This is also where compliance discussions take place.
How Decisions Compound
Each of these decisions is reasonable on its own. They compound in ways that aren't always obvious. A "single LLM, stateful, fully autonomous, tool-permissioned" agent is a different system from a "multi-LLM routing, stateless, human-in-the-loop, sandboxed" agent, even though both might solve the same nominal task. The architectural decisions are correlated, and writing them down (rather than letting them emerge implicitly from framework defaults) is what lets the team change one without quietly breaking another.
Agentic AI Architecture Examples
Three sketches of how this is composed in practice.
Customer Support Agent
A single-agent design with tool access to the order database, ticketing system, and refund API. Reflection layer on top so the agent self-checks its proposed responses before sending. Memory carries the conversation and pulls in prior tickets from the same customer. Refunds over a threshold trigger human-in-the-loop. Common, well-understood, hard to operate well at scale because the failure modes (over-eager refunds, hallucinated policies) are subtle. The interesting architecture decisions in this shape are usually two, and they sit deeper than they look. The first is how the refund threshold is configured (per customer, per product, or per time window). The second is how the agent communicates uncertainty to the human reviewer. Both feel like product decisions but live in the agent's prompt and tool descriptors.
Engineering / DevOps Agent
A multi-agent design typically comprises:
- A planner that decomposes high-level tasks into git operations, CI triggers, and observability queries.
- Specialist agents that handle each sub-task.
- Action permissions that are tightly scoped, read-only by default, with write actions requiring explicit approval.
- Episodic memory drawn from prior incidents and their resolutions.
The interesting architecture choice is how the agent's actions get attributed in the audit trail.
Multi-Agent Research and Planning
This is the shape of Catio's conversational architecture copilot, Archie, and the recommendation engine behind it. A planner agent decomposes architectural questions ("what's the right modernization plan for our data pipeline?") into specialist sub-queries; specialist agents reason over the live system graph and prior decisions; and a synthesis agent produces a recommendation with explicit trade-offs. Each agent's job is narrow; the value comes from how the planner composes them.
Challenges in Production Agentic AI Architecture
The "we shipped a demo, why doesn't this work in production" gap usually traces to one of these.
- Latency. Multi-step reasoning takes seconds, not milliseconds. Users have expectations from non-agentic UIs that don't carry over. Architecting for streaming and intermediate state matters more than picking a faster model.
- Cost. Token spend on a multi-step agentic interaction can dwarf the database, compute, and storage costs the same system would have incurred without LLMs. Routing, caching, and short-circuit paths for common cases are not optimizations; they're design requirements.
- Observability. Tracing a single user interaction through a multi-agent system can mean dozens of LLM calls, tool invocations, and memory reads. Without an observability layer designed for this, debugging is a guessing game.
- Evals and regression. Models, prompts, and tool descriptors change. Behavior changes with them, sometimes silently. An eval harness is mandatory, not optional.
- Prompt injection. Anything a user can put into the agent's context, an attacker can put as well. Production agents need defenses at the tool boundary, not just the model.
- Hallucination at the tool boundary. A confident-sounding wrong answer is bad. A confident wrong answer that triggers a tool call is worse. Validation at the action layer is where most teams under-invest.
- Tool misuse. Permissions creep. A capability that was safe last quarter becomes a foot gun once the agent receives new context. Auditing and revoking capabilities are real, ongoing jobs.
A couple of these deserve a closer look because they tend to bite in ways teams don't anticipate.
Latency compounds with the number of reasoning steps. A single LLM call in the 1-2-second range becomes a 15-second user wait once the agent completes 5 steps. Streaming intermediate state to the UI helps the user experience but doesn't shorten the actual work; the design fix is usually a combination of caching, sub-agent parallelism, and short-circuit paths that bypass reasoning entirely for the most common queries. The architecture decision worth writing down is the latency budget per request and which actions trigger which paths.
Observability is the silent killer of agentic systems that worked great in QA. Without per-step traces, structured tool-call logs, and the ability to replay an interaction with adjusted prompts or models, debugging becomes anecdotal. The teams that ship agentic systems successfully invest in observability early; the teams that ship demos and call them MVPs invariably regret skipping it.
How to Choose Your Agentic AI Architecture
A reasonable decision sequence, in roughly the order it should bind:
- Goal and risk profile. What's the task, who's harmed if the agent gets it wrong, and what's the budget for the wrong answer? This sets the human-in-the-loop posture before anything else.
- Tool surface. What actions does the agent need to take, and how are they permissioned? If you can't enumerate the tools, the architecture is premature.
- Reasoning kind. Symbolic, LLM-based, or hybrid? Driven by task complexity and cost tolerance.
- Single vs. multi-agent. If a single ReAct loop can plausibly solve the task, start there. Multi-agent systems cost more to operate; only adopt them when the task demands it.
- Memory model. Short-term, long-term, and episodic, with explicit policies for what gets written, retrieved, and forgotten.
- Planes. Orchestration, observability, security, governance. None of these is optional for production, even though they often get treated as such.
Choosing the architecture is itself an architectural decision. Catio's product was built to help with. If you'd find it useful to see how an agentic system maps to its own underlying decisions, the Architecture IDE is one place to do that.
What Comes Next
Patterns and components are the easy part. Decisions are the hard part. The teams that ship agentic systems that survive contact with production are the teams that treat the architecture as a system of decisions they revisit as the system learns what it actually needs.
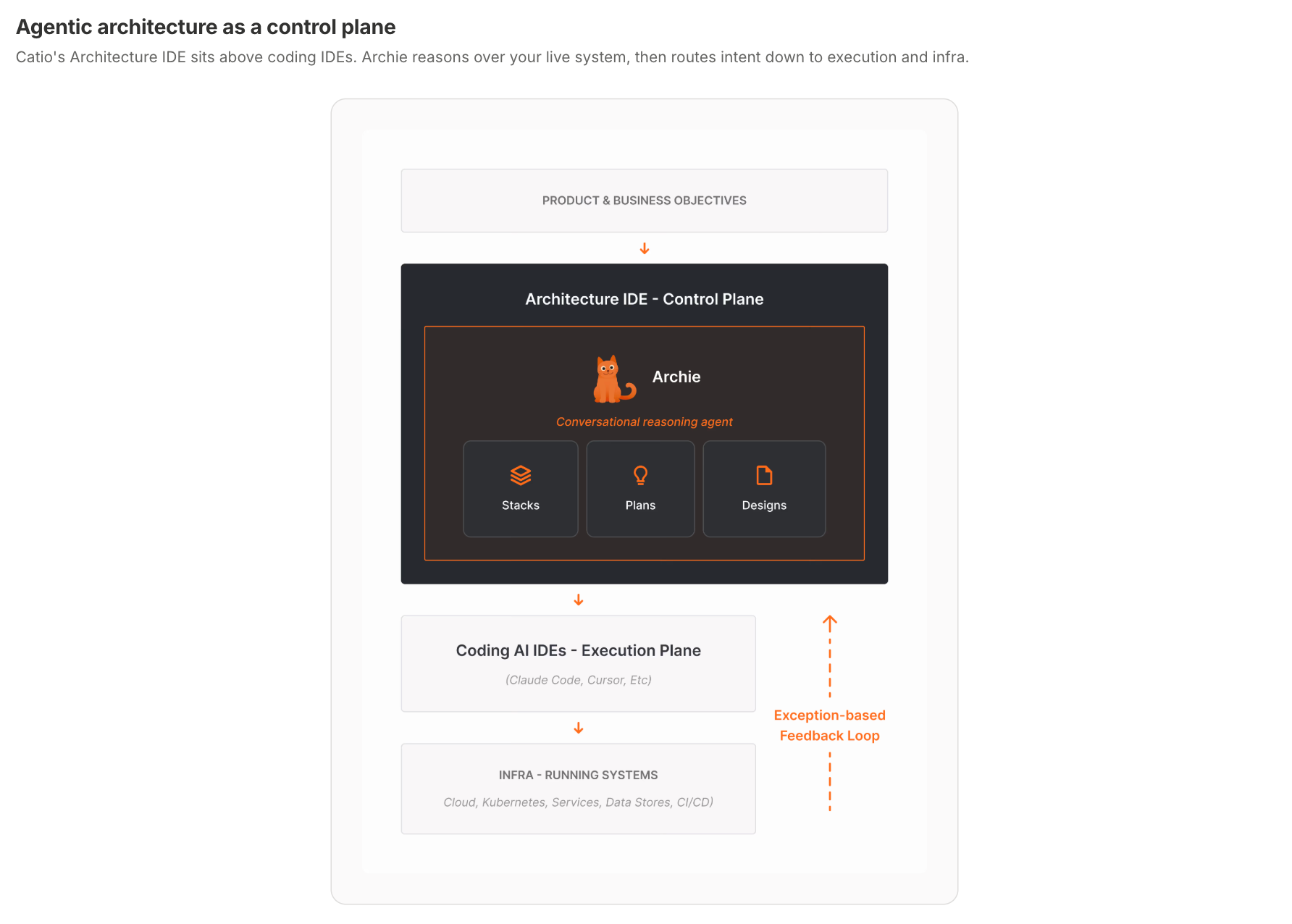
If you're designing an agentic system right now, see how Catio approaches agentic architecture as a decision problem, with live system context, explicit trade-offs, and a system of record for the decisions that shape what gets built. Start with a real architecture question and work backward from there.
Frequently Asked Questions
What are the components of agentic AI architecture?
Perception, reasoning, memory, and action are the four components that appear in nearly every production agentic system. Production designs add four cross-cutting planes (orchestration, observability, security, governance) that hold the components together at scale.
What's the difference between agentic AI and generative AI?
Generative AI produces content (text, code, images) in response to a prompt. Agentic AI uses generative models as one component of a larger system that perceives context, plans, retains memory, and takes action through tools. Generative AI is a capability; agentic AI is a system design that wraps that capability in a control loop.
What are the common agentic AI design patterns?
Single-agent (ReAct, Reflexion), multi-agent collaboration (router-workers, debate, voting), hierarchical/vertical (supervisor with specialists), graph-based/mesh, and reflection or self-correction layered on top. Production systems usually combine more than one.
Is a multi-agent system always better than a single-agent system?
No. Multi-agent designs are more expensive to operate (more tokens, harder observability) and only outperform single-agent on tasks where parallel exploration or specialization actually helps. Start with the simplest design that plausibly solves the task and add agents only when the cost is justified.
Share this Post

