June 20, 2026
Agentic AI Reference Architecture: Components & Layers

Most agentic AI systems start as a single LangChain notebook and end up structurally indistinguishable from every other production system teams have shipped. That's a clue. The shape of an agentic system in 2026 has mostly converged. The components are stable, the planes around them are well known, and the interesting work lies in how teams adapt the shape to their stack rather than in the shape itself.
This guide is the reference architecture. It covers the four agent layers (perception, reasoning, memory, action), the four cross-cutting planes (orchestration, observability, security, governance), the variants you'll choose between (single-agent, hierarchical, mesh, RAG-hybrid), how to adapt the reference to your existing infrastructure, and a worked example of how Catio's own multi-agent system maps onto it. It's written for architects, platform leads, and engineering managers building agentic systems that must withstand contact with real users and auditors.
What Is an Agentic AI Reference Architecture?
An agentic AI reference architecture is a canonical layered design for building production-grade autonomous AI systems. It captures the components that show up in nearly every working agentic system (perception, reasoning, memory, action) and the cross-cutting planes that hold those components together at scale (orchestration, observability, security, governance). The reference isn't prescriptive. It's a starting point you adapt, not a template you copy verbatim.
The distinction between a reference architecture and a solution architecture matters. The reference is the canonical shape the category has converged on. A solution architecture is one team's specific adaptation: which LLMs, which tools, which orchestration engine, which observability stack, sized for which workload. Most teams confuse the two and either over-engineer (treating the reference as a literal blueprint) or under-engineer (skipping the planes because the demo didn't need them). The reference is useful as a checklist. The solution architecture is what you actually deploy.
It's worth saying out loud why every production agentic system roughly follows this shape. The four components mirror the cognitive loop the system is automating (perceive, decide, remember, act). The four planes are operational necessities once the system is communicating with real users and downstream services. Skipping any of the planes works in a demo and fails in production, which is why most "we shipped a demo but couldn't get it to production" stories trace back to a missing plane.
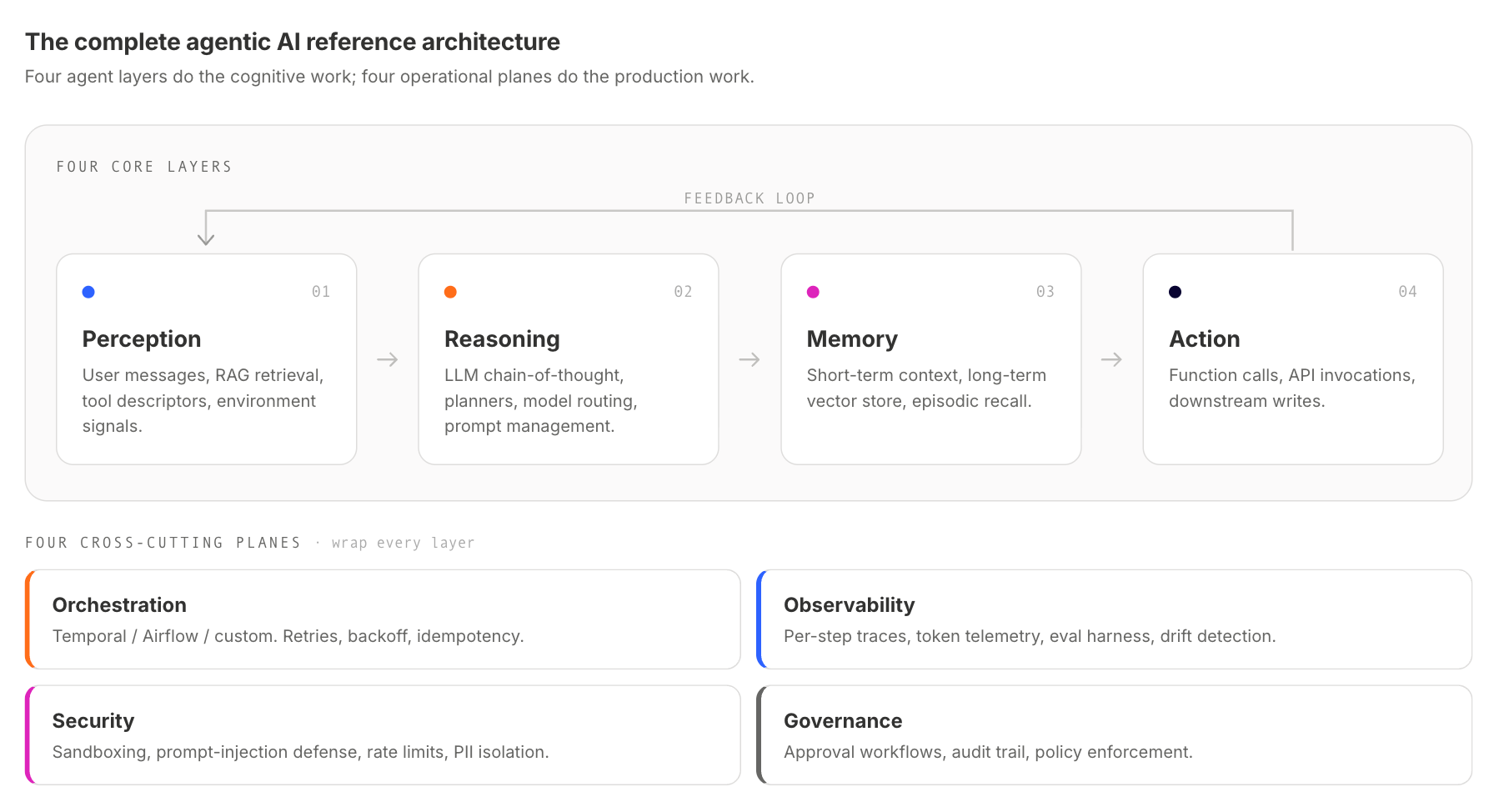
The Complete Agentic AI Reference Architecture
At a glance, the shape is four agent layers wrapped in four operational planes. The agent layers do the cognitive work. The planes do the production work.
Each row is the smallest unit a real production system contains. Most demos cover the first four. Most production deployments add the four planes once they start handling real traffic, and discover that the planes are where the actual engineering investment lives.
The broader treatment of how this shape relates to the patterns teams choose between (single-agent, multi-agent, hierarchical) lives in our agentic AI architecture post; this guide focuses on the reference itself rather than the pattern selection.
Core Agent Layers
The four components do the work the system was built to do. The interesting design choices in each are about what's in scope.
Perception Layer
Perception is how the agent takes in the world. The inputs are usually structured user messages, retrieved context from documents or knowledge bases, tool descriptors that specify what the agent can do, and environmental signals from the system in which the agent is deployed. The design choice that matters here is what counts as context that the agent should care about. Too little, and reasoning misfires; too much, and the token bill grows faster than the answer quality. Modern retrieval patterns (hybrid retrieval, re-ranking, context compression) live here.
Reasoning Layer
Reasoning is the part of the loop where the system gets from "here is what's happening" to "here is what to do." Production systems combine multiple approaches: symbolic reasoning for predictable cases, LLM-based chain-of-thought reasoning for ambiguous cases, and planners for tasks with large search spaces. Model routing (which LLM for which step) is a reasoning-layer concern; so is prompt management (the versioned, evaluated prompts the system uses), and so are the planner/critic loops that some patterns rely on. The interesting choice is what determines the route between modalities.
Memory Layer
LLMs are stateless. The memory layer is what makes the system look stateful to the user. Three flavors recur: short-term working memory (the current conversation or task), long-term memory (preferences, prior outcomes, embeddings in a vector store), and episodic memory (specific past experiences the agent can retrieve to inform new ones). The design choice that matters is the write-and-eviction policy. Memory without explicit policy grows until it's both expensive and useless. Memory with policy is one of the highest-leverage parts of the system. For the broader case where language models alone aren't sufficient, and the system needs a richer memory and reasoning surface, see our Beyond LLMs post.
Action Layer
Action is where the agent reaches into the world: function calls, API invocations, database writes, message sending, and downstream workflow triggering. The architectural choice that matters is what permissions the agent gets and how it earns them. Read-only sandboxed agents are easy to ship. Agents that can spend money, modify customer records, or change infrastructure need careful guardrails at the tool boundary. Most production designs land on tool-by-tool permissioning with capability-based access controls.

Orchestration Plane
Orchestration is the plane that's most often underbuilt and most often regretted. The job of orchestration is to coordinate the multi-step work the agent is doing: which step ran, what happened, what gets retried, what's idempotent, and what isn't.
The choice of workflow engine is the biggest commitment in this plane. Temporal is a common choice for agentic systems that need durable workflows and explicit state management. Airflow remains common for batch-oriented agent work that fits a DAG. Custom orchestration shows up in teams that want tight control and have the engineering capacity to build it. The wrong choice is "no orchestration engine," which produces systems where a tool call that fails halfway through a multi-step workflow leaves the system in an undefined state.
The retry, backoff, and idempotency story is what makes orchestration usable. Without idempotency guarantees on tool calls, retries become dangerous (you can send the same email three times). With them, the system can recover from transient failures without human intervention. The boundary between "tool call we can retry" and "tool call that has external side effects" is the most important property to write down explicitly.
Observability Plane
Observability is the plane that determines whether you can improve the system or only redeploy it. Without observability, debugging an agentic system in production is anecdotal. With it, the team has a substrate for evaluating, improving, and explaining the system's behavior.
The minimum observability investment is per-step traces (every reasoning step, every tool call, every memory read or write, captured with timing and outcome), structured tool-call logs (what the agent invoked, what came back, what it decided next), an eval harness (the offline test suite that catches regressions when prompts or models change), and drift detection on output quality (the production-quality signal that tells you whether the system has gotten quietly worse). Teams that ship agentic systems successfully invest in observability early; teams that ship demos and call them MVPs invariably regret skipping it.
The token telemetry piece is its own line item. Token spend on a multi-step agentic interaction can dwarf the database, compute, and storage costs the same system would have incurred without LLMs. Without per-request, per-model token tracking, the cost story is opaque, and the cost optimizations the team wants to make are impossible to defend.
Security Plane
Security at the agent boundary is structurally different from security at a traditional API boundary. An attacker doesn't need to bypass authentication if they can convince the agent to do something on their behalf. The defenses are split into a few categories.
Prompt injection defenses sit at the input boundary. The defense isn't "filter prompts for malicious content" (that doesn't work). The defense is structural separation between user input and trusted instructions, treating retrieved context as untrusted, and constraining what the agent can do regardless of what it's been told to do.
Tool-call rate limits, sandboxing, and per-tool permission scoping sit at the action boundary. The principle is that the agent can be tricked into wanting to do something harmful, and the harm must be bounded by the boundary through which the agent acts, rather than by the model that decides.
PII and data isolation sit at the boundaries of memory and observability. The agent's logs, traces, and long-term memory are now places where sensitive data accumulates by accident. Treating them like any other regulated data store is mandatory.
Governance Plane
Governance is where the architecture decisions made at design time get enforced at runtime. Approval workflows for high-risk actions (refunds over a threshold, customer record changes, infrastructure changes), audit trail for everything the agent does, policy enforcement for what the agent is allowed to attempt, and explainability for why a given decision was made.
The category overlap with security is real but distinct. Security keeps the agent from being weaponized. Governance keeps the agent from doing legitimate-but-undesirable things at scale. Both matter, and both are usually underbuilt at the demo stage.
The decisions about which actions need approval and which can run autonomously are themselves architecture decisions the team is committing to. Writing them down explicitly (rather than encoding them implicitly in tool descriptors) is what makes the policy reviewable.

Reference Architecture Variants
The reference shape supports several common variants. The choice between them comes down to the work the system is doing.
Single-Agent
One agent, one reasoning loop, one tool surface. The simplest variant. Works for narrow tasks (a customer support agent, a code search agent) where decomposition would add cost without adding value. Easiest to operate, easiest to debug, hits a ceiling on task complexity.
Hierarchical Multi-Agent
A supervisor agent delegates to specialist agents. The supervisor decomposes the task and routes; specialists do narrow work. Works when sub-tasks are heterogeneous and a single planner can usefully route between them. The supervisor's prompt becomes the most important artifact in the system.
Mesh / Collaborative Multi-Agent
Agents communicate peer-to-peer along defined edges in a graph, rather than through a central coordinator. Useful for workflows that mirror a real process (a supply chain, a multi-step approval, a research pipeline). Higher operational complexity than hierarchical designs, but better fit for workflows with cyclic dependencies. The broader pattern catalog for this lives in our supercharging AI with multi-agent systems post.
Retrieval-Augmented Agent (RAG Hybrid)
A single or multi-agent design that ties the reasoning layer tightly to a retrieval system. The agent's effective intelligence is bounded by what the retrieval system can surface, which makes the perception layer disproportionately important. RAG-hybrid is the most common production pattern in 2026 for agents that need to reason over an organization-specific knowledge base.
How to Adapt This Reference Architecture to Your Stack
The reference is portable. The adaptation is opinionated.
When You're on AWS / Azure / GCP
Each major cloud provider has primitives that map onto the reference layers. Bedrock, Vertex AI, and Azure AI Foundry each provide model routing, tool integration, and orchestration patterns that the reference architecture's layers slot into. The trade-off is the usual cloud one: faster to ship, harder to move later. For teams committed to a single cloud, the provider's agentic services are often the right pragmatic choice.
When You're Already on a Vendor Framework
LangChain, LlamaIndex, AutoGen, CrewAI, and the rest of the framework ecosystem each implement a subset of the reference, often glued together with MCP (the Model Context Protocol, which is a protocol for connecting models and agents to tools and context, not an agent framework on its own). The honest framing is that frameworks accelerate the early stages of building agentic systems and create lock-in at the later stages. Most production teams end up with a hybrid: framework-style scaffolding for rapid iteration, custom code at the planes (observability, security, governance) where the framework's defaults don't fit.
Build vs Buy by Layer
The right answer is rarely all-build or all-buy. The pattern that holds up is: buy the model layer (no team is going to out-train OpenAI, Anthropic, or Google), own the orchestration and observability design (whether implemented with internal systems, managed tools, or a hybrid, they have to fit your existing infrastructure), and decide secrets/governance based on your compliance posture. The framing connects to the broader emerging architecture patterns for the AI-native enterprise we've covered separately.
How Catio Approaches This Architecture
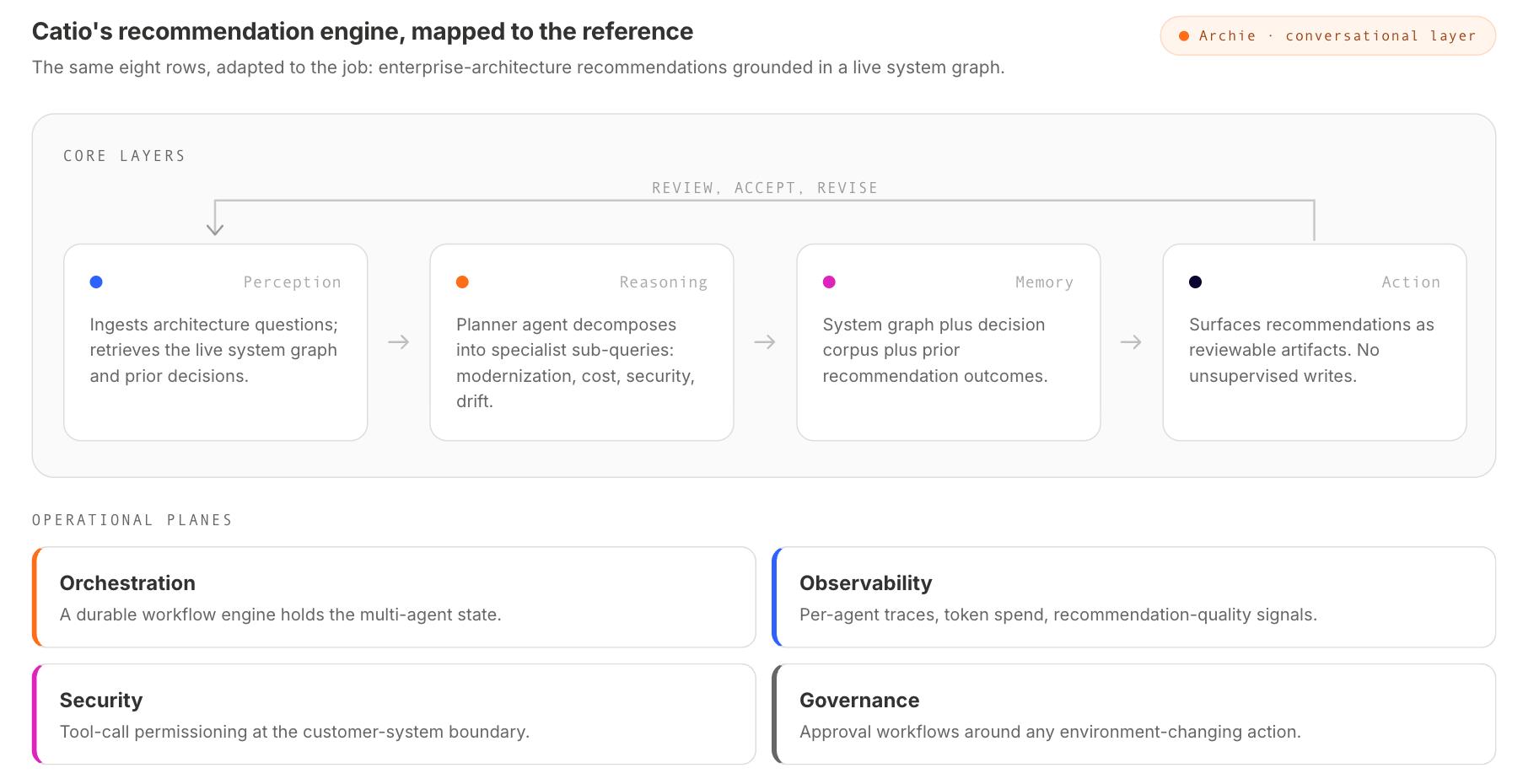
Catio's own multi-agent recommendation engine for enterprise architecture is a working example of the reference architecture in production. The shape maps roughly as follows.
The perception layer ingests architecture questions ("what's the right modernization plan for our data pipeline?") and retrieves the relevant subset of the live system graph and prior architecture decisions. The reasoning layer is a planner agent that decomposes the question into specialist sub-queries, each handled by a specialist agent (modernization, cost, security, drift detection). The memory layer is hybrid: short-term context tracks the current question; long-term memory holds the system graph and the decision corpus; episodic memory holds prior recommendations and their outcomes. The action layer surfaces recommendations as artifacts the team can review, accept, or revise; it doesn't write to the running system unsupervised.
Around the core, the four planes do their work. Orchestration runs on a workflow engine that durably stores the multi-agent state. Observability captures per-agent traces, token spend, and recommendation-quality signals. Security applies tool-call permissioning at the boundary where agents interact with the customer's system. Governance keeps approval workflows around any action that changes the customer's environment. The shape is the reference; the adaptation is specific to the job Catio's product does.
We've also written about Archie, our conversational architecture copilot, the user-facing layer that sits atop the recommendation engine. The two together illustrate the reference architecture working in a real product, not as a blueprint, and they're the part of Catio most directly built on the shape this guide describes.
What Comes Next
The reference architecture is the easy part. The hard part is the adaptation, where the architectural decisions you make (which orchestration engine, which observability stack, which governance policy) determine whether the system survives contact with production.
If you're designing an agentic system and want a place to land those decisions so they can be revisited as the system evolves, see how Catio treats agentic architecture as a system of decisions tied to live state, rather than as a static diagram that ages the moment you draw it.
Frequently Asked Questions
What are the components of an agentic AI reference architecture?
Perception, reasoning, memory, and action are the four core layers. Orchestration, observability, security, and governance are the four cross-cutting planes. Most production-grade agentic systems need to account for all eight, even if some are lightweight in the first version. The variation is in implementation and weight, not in scope.
What's the difference between reference architecture and design patterns?
A reference architecture is the canonical layered shape that the category has converged on. Design patterns (single-agent ReAct, multi-agent debate, hierarchical supervisor, etc.) are choices within the reference about how the components relate. The reference says what the parts are; the patterns say how they connect.
Do I need all of these layers to ship an agent?
No, but a demo can skip the four planes while a production deployment cannot. The boundary is reached when the system starts handling real users, downstream services, and auditors. Most "we shipped a demo but couldn't productize" stories trace back to skipping one of the planes.
How is this different from a traditional ML architecture?
Traditional ML architectures focus on data pipelines, training, evaluation, and serving for a fixed model that produces predictions. Agentic AI architectures wrap models in a control loop where the system perceives, decides, remembers, and acts autonomously across multiple steps. The shift is from "deploy a model" to "deploy a system that uses models as one of its components."
Share this Post

